Recovery Point Objective (RPO)
A recovery point objective (RPO) is defined by business continuity planning. It is the maximum targeted period in which data might be lost from an IT service due to a major incident. The RPO gives systems designers a limit to work to.
Data Loss Period based on below calculation

Recovery Time Objective (RTO)
The recovery time objective (RTO) is the targeted duration of time and a service level within which a business process must be restored after a disaster (or disruption) in order to avoid unacceptable consequences associated with a break in business continuity.

Recovery Point Objective (RPO)
The disaster recovery term Recovery Point Objective (RPO) is a widely used term. However, it’s often difficult to provide a simple definition and explain its important in the recovery process. But here it goes…
Recovery Point Objective is the point in time you can recover to in the event of a disaster.
So, if you have a disaster (data corruption, ransomware. power outage, user error, etc.) then you will lose all of the data up to your set RPO. If you have an RPO of 4 hours on your critical applications then this means you would lose 4 hours of data, as 4 hours ago is the last point in time to which you can recover.
The cost of just 1 hour of lost data for any size business can be a significant amount and as you scale upwards this becomes an even larger impact. If we take a sample organization with a turnover of $100m you can see the potential impact:
It’s impossible to know when a disaster will strike and how much data loss will occur. You could be lucky and have a disaster during off hours and lose no data, but this assumes you even have the concept of “off hours” in your organization. Or you could be really unlucky and have a disaster strike at your busiest period. Either way, expect the unexpected!
Due to the importance of RPO on data loss, it is recommended to agree on an acceptable and achievable RPO on a per application basis with basic SLAs such as the below:
- CRM System — 1 hour RPO
- Finance System — 1 hour RPO
- Email — 2 hour RPO
- File Servers — 4 hour RPO
- Directory Service — 8 hour RPO
- Print Servers — 24 hour RPO
- Development Servers — 24 hour RPO
If you have a BC/DR plan to deliver the above RPOs, you may think you are covered, but you could be wrong.
The reason being is that you would always be “red lining” your achieved RPO to your SLA. Meaning that by replicating on an hourly basis with perhaps a SAN based snapshot, the best you will ever do is meet the SLA. However, if there is a huge amount of data change you might start to miss that SLA and not to able to recover to a point acceptable to the business.
You should always aim to achieve the lowest RPO possible, then configure alerts to warn if you are in danger of the achieved RPO getting close to your defined SLA. In order to ensure low priority applications don’t impact the RPO on high priority applications, a priority and Quality of Service (QoS) setting should be applied to individual replication streams. This ensures they are prioritized accordingly in the circumstances of high IO and/or low bandwidth.
By applying QoS you can ensure that any available bandwidth is used to maintain a consistently low RPO across all of your applications, yet if the bandwidth becomes constrained only the high priority applications continue to maintain the low RPO.
Another term you should know is the Recovery Time Objective (RTO), which can be defined as: “The time that it takes to recover data and applications”. This means that in the event of a disaster, such as a system wide virus, a user error deleting production data, or a key hardware failure, the RTO is the time it will take to recover from this disaster and have the data and applications back online and running in your recovery site
Recovery Time Objective (RTO)
In disaster recovery the term Recovery Time Objective (RTO) can simply be defined as:
“The time that it takes to recover data and applications”.
This means that in the event of a disaster, such as a system wide virus, a user error deleting production data, or a key hardware failure, the RTO is the time it will take to recover from this disaster and have the data and applications back online and running in your recovery site.
The cost of the downtime associated with waiting for applications and data to be recovered can result in significant loss in revenue and productivity, as your business may have no applications available in order to continue generating revenue. In even the smallest of organizations this can be a significant figure and below is an example for a company with a turnover of $100m:
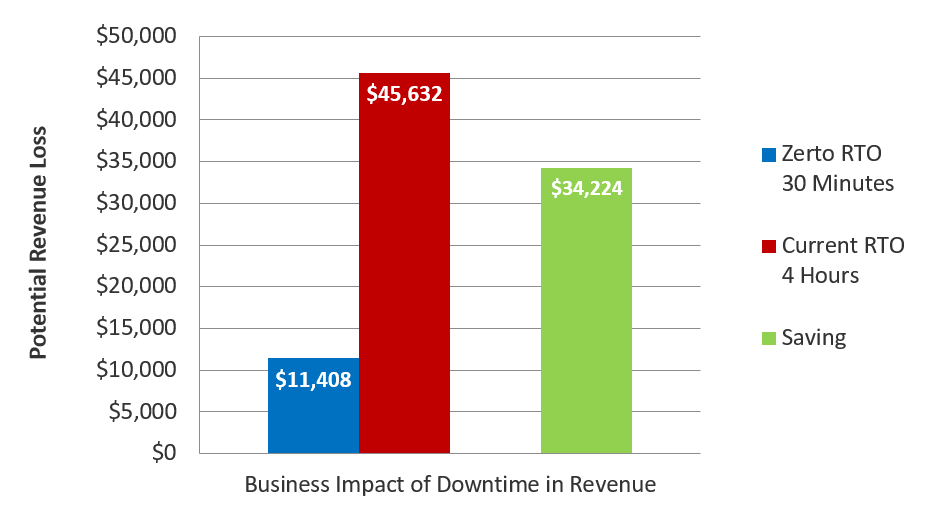
In this example you can see the potential revenue impact is a significant amount and this is the most basic of calculations of the annual revenue, divided by days in the year and hours in the day. The actual figure can be significantly worse if the disaster occurs in working hours. Additionally, this calculation doesn’t even attempt to quantify the impact on customers, brand identity, market perception, suppliers and share price which can increase the impact exponentially.
It is therefore important for any organization to try and attain the lowest possible RTO in order to minimize the impact of a disaster in a timely manner if and when required. Your RTO should be defined on a per application basis in order to prioritize the recovery of certain applications, in advance of others, depending on their level of criticality. This has the added benefit of ensuring that revenue generating applications are recovered first and ensuring that the IT staff focus on these before anything else.. An example RTO SLA could be:
- CRM System — 4 hour RTO
- Finance System — 4 hour RTO
- Email — 4 hour RTO
- File Servers — 4 hour RTO
- Directory Service — 2 hour RTO
- Print Servers — 24 hour RTO
- Dev Servers — 24 hour RTO
Achieving the above RTOs with any BC/DR technology is not as easy as it seems. Just registering and powering on Virtual Machines (VMs) is not your true RTO and nor should it be the RTO that you communicate as an achievable SLA to the business.
Registering and Powering on a VM is the simplest part of any recovery operation. The most complex and time consuming part is:
- Reconfiguring the VMs to run in the recovery site (such as MAC and IP address changes).
- Restoring from a working point in time where data is consistent.
- Finally ensuring all of the applications can communicate with each other and that they are up and running.
All of this should be done before communicating to the business that the application is back online and ready to use. The time that this whole process takes is your actual RTO and is the one that should be defined in your SLA.
By utilizing a BC/DR technology that can automate the process of registering, powering on VMs in the correct order and automatically reconfiguring IP and MAC addresses, you are going to give yourself the best shot and maintaining a low RTO. If this technology also allows you to try specific points in time, then rollback to a previous point in time, if the first recovery does not work, then you are ensuring recovery is not a “one shot” thing but rather a process.
In order to benchmark your RTO and tweak your BC/DR plan to minimize the time, testing is a must. By testing your plan with a BC/DR technology that allows for testing with no downtime in production, or break in the replication, you can perform a test during working hours to ensure that: first of all you are able recover, then you can run through the recovery operation multiple times to get your RTO as low as possible.
I hope this has given you a good insight into RTO and the things you should take into consideration when applying RTO SLAs to your applications, and how you prove they are achievable.
The disaster recovery term Recovery Point Objective (RPO) is also a widely used term, which means: “The point in time you can recover to in the event of a disaster”. So, if you have a disaster (data corruption, ransomware. power outage, user error, etc.) then you will lose all of the data up to your set RPO. If you have an RPO of 4 hours on your critical applications then this means you would lose 4 hours of data, as 4 hours ago is the last point in time to which you can recover.
Great blog... I found vital information on AWS RTO RPO and explain every term very well. Thanks for sharing such useful and well written blog post.
ReplyDelete