NVIDIA - Amazon EC2 Instances with P and G Series
New models will be faster on a GPU instance than a CPU instance. You can scale sub-linearly when you have multi-GPU instances or if you use distributed training across many instances with GPUs.
- Amazon EC2 P3 Instances have up to 8 NVIDIA Tesla V100 GPUs.
- Amazon EC2 P2 Instances have up to 16 NVIDIA NVIDIA K80 GPUs.
- Amazon EC2 G3 Instances have up to 4 NVIDIA Tesla M60 GPUs.
- Check out EC2 Instance Types and choose Accelerated Computing to see the different GPU instance options.
New – Amazon EC2 Instances with Up to 8 NVIDIA Tesla V100 GPUs (P3)
Driven by customer demand and made possible by on-going advances in the state-of-the-art, we’ve come a long way since the original m1.small instance that launched in 2006, with instances that emphasize compute power, burstable performance, memory size, local storage, and accelerated computing.
The New P3
Today we are making the next generation of GPU-powered EC2 instances available in four AWS regions. Powered by up to eight NVIDIA Tesla V100 GPUs, the P3 instances are designed to handle compute-intensive machine learning, deep learning, computational fluid dynamics, computational finance, seismic analysis, molecular modeling, and genomics workloads.
P3 instances use customized Intel Xeon E5-2686v4 processors running at up to 2.7 GHz. They are available in three sizes (all VPC-only and EBS-only):
| Model | NVIDIA Tesla V100 GPUs | GPU Memory | NVIDIA NVLink | vCPUs | Main Memory | Network Bandwidth | EBS Bandwidth |
| p3.2xlarge | 1 | 16 GiB | n/a | 8 | 61 GiB | Up to 10 Gbps | 1.5 Gbps |
| p3.8xlarge | 4 | 64 GiB | 200 GBps | 32 | 244 GiB | 10 Gbps | 7 Gbps |
| p3.16xlarge | 8 | 128 GiB | 300 GBps | 64 | 488 GiB | 25 Gbps | 14 Gbps |
Each of the NVIDIA GPUs is packed with 5,120 CUDA cores and another 640 Tensor cores and can deliver up to 125 TFLOPS of mixed-precision floating point, 15.7 TFLOPS of single-precision floating point, and 7.8 TFLOPS of double-precision floating point. On the two larger sizes, the GPUs are connected together via NVIDIA NVLink 2.0 running at a total data rate of up to 300 GBps. This allows the GPUs to exchange intermediate results and other data at high speed, without having to move it through the CPU or the PCI-Express fabric.
What’s a Tensor Core?
I had not heard the term Tensor core before starting to write this post. According to this very helpful post on the NVIDIA Blog, Tensor cores are designed to speed up the training and inference of large, deep neural networks. Each core is able to quickly and efficiently multiply a pair of 4×4 half-precision (also known as FP16) matrices together, add the resulting 4×4 matrix to another half or single-precision (FP32) matrix, and store the resulting 4×4 matrix in either half or single-precision form. Here’s a diagram from NVIDIA’s blog post:
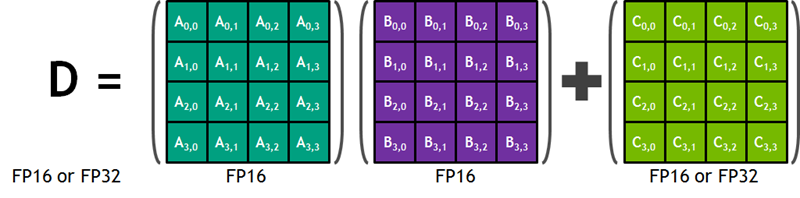
This operation is in the innermost loop of the training process for a deep neural network, and is an excellent example of how today’s NVIDIA GPU hardware is purpose-built to address a very specific market need. By the way, the mixed-precision qualifier on the Tensor core performance means that it is flexible enough to work with with a combination of 16-bit and 32-bit floating point values.
Performance in Perspective
I always like to put raw performance numbers into a real-world perspective so that they are easier to relate to and (hopefully) more meaningful. This turned out to be surprisingly difficult, given that the eight NVIDIA Tesla V100 GPUs on a single p3.16xlarge can do 125 trillion single-precision floating point multiplications per second.
Let’s go back to the dawn of the microprocessor era, and consider the Intel 8080A chip that powered the MITS Altair that I bought in the summer of 1977. With a 2 MHz clock, it was able to do about 832 multiplications per second (I used this data and corrected it for the faster clock speed). The p3.16xlarge is roughly 150 billion times faster. However, just 1.2 billion seconds have gone by since that summer. In other words, I can do 100x more calculations today in one second than my Altair could have done in the last 40 years!
What about the innovative 8087 math coprocessor that was an optional accessory for the IBM PC that was announced in the summer of 1981? With a 5 MHz clock and purpose-built hardware, it was able to do about 52,632 multiplications per second. 1.14 billion seconds have elapsed since then, p3.16xlarge is 2.37 billion times faster, so the poor little PC would be barely halfway through a calculation that would run for 1 second today.
Ok, how about a Cray-1? First delivered in 1976, this supercomputer was able to perform vector operations at 160 MFLOPS, making the p3.x16xlarge 781,000 times faster. It could have iterated on some interesting problem 1500 times over the years since it was introduced.
Comparisons between the P3 and today’s scale-out supercomputers are harder to make, given that you can think of the P3 as a step-and-repeat component of a supercomputer that you can launch on as as-needed basis.
Run One Today
In order to take full advantage of the NVIDIA Tesla V100 GPUs and the Tensor cores, you will need to use CUDA 9 and cuDNN7. These drivers and libraries have already been added to the newest versions of the Windows AMIs and will be included in an updated Amazon Linux AMI that is scheduled for release on November 7th. New packages are already available in our repos if you want to to install them on your existing Amazon Linux AMI.
The newest AWS Deep Learning AMIs come preinstalled with the latest releases of Apache MxNet, Caffe2, and Tensorflow (each with support for the NVIDIA Tesla V100 GPUs), and will be updated to support P3 instances with other machine learning frameworks such as Microsoft Cognitive Toolkit and PyTorch as soon as these frameworks release support for the NVIDIA Tesla V100 GPUs. You can also use the NVIDIA Volta Deep Learning AMI for NGC.
Amazon EC2 P2 Instances
Amazon EC2 P2 Instances are powerful, scalable instances that provide GPU-based parallel compute capabilities. For customers with graphics requirements, see G2 instances for more information.
P2 instances, designed for general-purpose GPU compute applications using CUDA and OpenCL, are ideally suited for machine learning, high performance databases, computational fluid dynamics, computational finance, seismic analysis, molecular modeling, genomics, rendering, and other server-side workloads requiring massive parallel floating point processing power.
Use the Amazon Linux AMI, pre-installed with popular deep learning frameworks such as Caffe and Mxnet, so you can get started quickly. You can also use the NVIDIA AMI with GPU driver and CUDA toolkit pre-installed for rapid onboarding.
P2 Features


Powerful Performance
P2 instances provide up to 16 NVIDIA K80 GPUs, 64 vCPUs and 732 GiB of host memory, with a combined 192 GB of GPU memory, 40 thousand parallel processing cores, 70 teraflops of single precision floating point performance, and over 23 teraflops of double precision floating point performance. P2 instances also offer GPUDirect™ (peer-to-peer GPU communication) capabilities for up to 16 GPUs, so that multiple GPUs can work together within a single host.
Scalable
Cluster P2 instances in a scale-out fashion with Amazon EC2 ENA-based Enhanced Networking, so you can run high-performance, low-latency compute grid. P2 is well-suited for distributed deep learning frameworks, such as MXNet, that scale out with near perfect efficiency.
Amazon EC2 G3 Instances
Accelerate your graphics-intensive workloads with powerful GPU instances 
Amazon EC2 G3 instances are the latest generation of Amazon EC2 GPU graphics instances that deliver a powerful combination of CPU, host memory, and GPU capacity. G3 instances are ideal for graphics-intensive applications such as 3D visualizations, mid to high-end virtual workstations, virtual application software, 3D rendering, application streaming, video encoding, gaming, and other server-side graphics workloads.
G3 instances provides access to NVIDIA Tesla M60 GPUs, each with up to 2,048 parallel processing cores, 8 GiB of GPU memory, and a hardware encoder supporting up to 10 H.265 (HEVC) 1080p30 streams and up to 18 H.264 1080p30 streams. With the latest driver releases, these GPUs provide support for OpenGL, DirectX, CUDA, OpenCL, and Capture SDK (formerly known as GRID SDK).
Accelerated Computing
Accelerated computing instances use hardware accelerators, or co-processors, to perform functions, such as floating point number calculations, graphics processing, or data pattern matching, more efficiently than is possible in software running on CPUs.
P3 instances are the latest generation of general purpose GPU instances.
Features:
- Up to 8 NVIDIA Tesla V100 GPUs, each pairing 5,120 CUDA Cores and 640 Tensor Cores
- High frequency Intel Xeon E5-2686 v4 (Broadwell) processors for p3.2xlarge, p3.8xlarge, and p3.16xlarge.
- High frequency 2.5 GHz (base) Intel Xeon P-8175M processors for p3dn.24xlarge.
- Supports NVLink for peer-to-peer GPU communication
- Provides up to 100 Gbps of aggregate network bandwidth.
- EFA support on p3dn.24xlarge instances
P2 instances are intended for general-purpose GPU compute applications.
Features:
- High frequency Intel Xeon E5-2686 v4 (Broadwell) processors
- High-performance NVIDIA K80 GPUs, each with 2,496 parallel processing cores and 12GiB of GPU memory
- Supports GPUDirect™ for peer-to-peer GPU communications
- Provides Enhanced Networking using Elastic Network Adapter (ENA) with up to 25 Gbps of aggregate network bandwidth within a Placement Group
- EBS-optimized by default at no additional cost
G4 instances are designed to help accelerate machine learning inference and graphics-intensive workloads.
Features:
- 2nd Generation Intel Xeon Scalable (Cascade Lake) processors
- NVIDIA T4 Tensor Core GPUs
- Up to 100 Gbps of networking throughput
- Up to 1.8 TB of local NVMe storage
G3 instances are optimized for graphics-intensive applications.
Features:
- High frequency Intel Xeon E5-2686 v4 (Broadwell) processors
- NVIDIA Tesla M60 GPUs, each with 2048 parallel processing cores and 8 GiB of video memory
- Enables NVIDIA GRID Virtual Workstation features, including support for 4 monitors with resolutions up to 4096x2160. Each GPU included in your instance is licensed for one “Concurrent Connected User"
- Enables NVIDIA GRID Virtual Application capabilities for application virtualization software like Citrix XenApp Essentials and VMware Horizon, supporting up to 25 concurrent users per GPU
- Each GPU features an on-board hardware video encoder designed to support up to 10 H.265 (HEVC) 1080p30 streams and up to 18 H.264 1080p30 streams, enabling low-latency frame capture and encoding, and high-quality interactive streaming experiences
- Enhanced Networking using the Elastic Network Adapter (ENA) with 25 Gbps of aggregate network bandwidth within a Placement Group
F1 instances offer customizable hardware acceleration with field programmable gate arrays (FPGAs).
Instances Features:
- High frequency Intel Xeon E5-2686 v4 (Broadwell) processors
- NVMe SSD Storage
- Support for Enhanced Networking
FPGA Features:
- Xilinx Virtex UltraScale+ VU9P FPGAs
- 64 GiB of ECC-protected memory on 4x DDR4
- Dedicated PCI-Express x16 interface
- Approximately 2.5 million logic elements
- Approximately 6,800 Digital Signal Processing (DSP) engines
- FPGA Developer AMI
Storage Optimized
Storage optimized instances are designed for workloads that require high, sequential read and write access to very large data sets on local storage. They are optimized to deliver tens of thousands of low-latency, random I/O operations per second (IOPS) to applications.
This I3 instance family provides Non-Volatile Memory Express (NVMe) SSD-backed instance storage optimized for low latency, very high random I/O performance, high sequential read throughput and provide high IOPS at a low cost. I3 also offers Bare Metal instances (i3.metal), powered by the Nitro System, for non-virtualized workloads, workloads that benefit from access to physical resources, or workloads that may have license restrictions.
Features:
- High Frequency Intel Xeon E5-2686 v4 (Broadwell) Processors with base frequency of 2.3 GHz
- Up to 25 Gbps of network bandwidth using Elastic Network Adapter (ENA)-based Enhanced Networking
- High Random I/O performance and High Sequential Read throughput
- Support bare metal instance size for workloads that benefit from direct access to physical processor and memory
| Instance | vCPU* | Mem (GiB) | Local Storage (GB) | Networking Performance (Gbps) |
| i3.large | 2 | 15.25 | 1 x 475 NVMe SSD | Up to 10 |
| i3.xlarge | 4 | 30.5 | 1 x 950 NVMe SSD | Up to 10 |
| i3.2xlarge | 8 | 61 | 1 x 1,900 NVMe SSD | Up to 10 |
| i3.4xlarge | 16 | 122 | 2 x 1,900 NVMe SSD | Up to 10 |
| i3.8xlarge | 32 | 244 | 4 x 1,900 NVMe SSD | 10 |
| i3.16xlarge | 64 | 488 | 8 x 1,900 NVMe SSD | 25 |
| i3.metal | 72** | 512 | 8 x 1,900 NVMe SSD | 25 |
All instances have the following specs:
- 2.3 GHz Intel Xeon E5 2686 v4 Processor
- Intel AVX†, Intel AVX2†, Intel Turbo
- EBS Optimized
- Enhanced Networking†
Use Cases
NoSQL databases (e.g. Cassandra, MongoDB, Redis), in-memory databases (e.g. Aerospike), scale-out transactional databases, data warehousing, Elasticsearch, analytics workloads.
This I3en instance family provides dense Non-Volatile Memory Express (NVMe) SSD instance storage optimized for low latency, high random I/O performance, high sequential disk throughput, and offers the lowest price per GB of SSD instance storage on Amazon EC2. I3en also offers Bare Metal instances (i3en.metal), powered by the Nitro System, for non-virtualized workloads, workloads that benefit from access to physical resources, or workloads that may have license restrictions.
Features:
- Up to 60 TB of NVMe SSD instance storage
- Up to 100 Gbps of network bandwidth using Elastic Network Adapter (ENA)-based Enhanced Networking
- High random I/O performance and high sequential disk throughput
- Up to 3.1 GHz Intel® Xeon® Scalable (Skylake) processors with new Intel Advanced Vector Extension (AVX-512) instruction set
- Powered by the AWS Nitro System, a combination of dedicated hardware and lightweight hypervisor
- Support bare metal instance size for workloads that benefit from direct access to physical processor and memory
- Support for Elastic Fabric Adapter on i3en.24xlarge
| Instance | vCPU | Mem (GiB) | Local Storage (GB) | Network Bandwidth |
| i3en.large | 2 | 16 | 1 x 1,250 NVMe SSD | Up to 25 Gbps |
| i3en.xlarge | 4 | 32 | 1 x 2,500 NVMe SSD | Up to 25 Gbps |
| i3en.2xlarge | 8 | 64 | 2 x 2,500 NVMe SSD | Up to 25 Gbps |
| i3en.3xlarge | 12 | 96 | 1 x 7,500 NVMe SSD | Up to 25 Gbps |
| i3en.6xlarge | 24 | 192 | 2 x 7,500 NVMe SSD | 25 Gbps |
| i3en.12xlarge | 48 | 384 | 4 x 7,500 NVMe SSD | 50 Gbps |
| i3en.24xlarge | 96 | 768 | 8 x 7,500 NVMe SSD | 100 Gbps |
| i3en.metal | 96 | 768 | 8 x 7,500 NVMe SSD | 100 Gbps |
All instances have the following specs:
- 3.1 GHz all core turbo Intel® Xeon® Scalable (Skylake) processors
- Intel AVX†, Intel AVX2†, Intel AVX-512†, Intel Turbo
- EBS Optimized
- Enhanced Networking
Use cases
NoSQL databases (e.g. Cassandra, MongoDB, Redis), in-memory databases (e.g. SAP HANA, Aerospike), scale-out transactional databases, distributed file systems, data warehousing, Elasticsearch, analytics workloads.
D2 instances feature up to 48 TB of HDD-based local storage, deliver high disk throughput, and offer the lowest price per disk throughput performance on Amazon EC2.
Features:
- High-frequency Intel Xeon E5-2676 v3 (Haswell) processors
- HDD storage
- Consistent high performance at launch time
- High disk throughput
- Support for Enhanced Networking
All instances have the following specs:
- 2.4 GHz Intel Xeon E5-2676 v3 Processor
- Intel AVX†, Intel AVX2†, Intel Turbo
- EBS Optimized
- Enhanced Networking†
Use Cases
Massively Parallel Processing (MPP) data warehousing, MapReduce and Hadoop distributed computing, distributed file systems, network file systems, log or data-processing applications.
H1 instances feature up to 16 TB of HDD-based local storage, deliver high disk throughput, and a balance of compute and memory.
Features:
- Powered by 2.3 GHz Intel® Xeon® E5 2686 v4 processors (codenamed Broadwell)
- Up to 16TB of HDD storage
- High disk throughput
- ENA enabled Enhanced Networking up to 25 Gbps
| Instance | vCPU* | Mem (GiB) | Networking Performance | Storage (GB) |
| h1.2xlarge | 8 | 32 | Up to 10 Gigabit | 1 x 2,000 HDD |
| h1.4xlarge | 16 | 64 | Up to 10 Gigabit | 2 x 2,000 HDD |
| h1.8xlarge | 32 | 128 | 10 Gigabit | 4 x 2,000 HDD |
| h1.16xlarge | 64 | 256 | 25 Gigabit | 8 x 2,000 HDD |
All instances have the following specs:
- 2.3 GHz Intel Xeon E5 2686 v4 Processor
- Intel AVX†, Intel AVX2†, Intel Turbo
- EBS Optimized
- Enhanced Networking†
Use Cases
MapReduce-based workloads, distributed file systems such as HDFS and MapR-FS, network file systems, log or data processing applications such as Apache Kafka, and big data workload clusters.

ReplyDeleteInformative Blog
AWS Online Training
AWS Training
AWS certification training
This is a very nice one and gives in-depth information. I am really happy with the quality and presentation of the article. I’d really like to appreciate the efforts you get with writing this post. Thanks for sharing
ReplyDeleteAWS classes in pune
We can share this blog to anyone related to this topic. Thanks for sharing.
ReplyDeleteAWS Training In Chennai
AWS Online Training
AWS Training in Bangalore
Thanks you and excellent and good to see the best software training courses for freshers and experience candidates to upgade the next level in an Software Industries Technologies,
ReplyDeleteAWS Training in Bangalore
AWS course in Bangalore
Best AWS Training Institutes in Bangalore
Cloud Computing courses in Bangalore
Thanks you and excellent and good to see the best software training courses for freshers and experience candidates to upgade the next level in an Software Industries Technologies,
ReplyDeleteAWS Training in Bangalore
AWS course in Bangalore
AWS Training Bangalore
AWS course Bangalore
Thanks You for Sharing the Blogger content
ReplyDeleteAWS Training in Bangalore
AWS course in Bangalore
AWS Online Training in Bangalore
AWS Online Courses in Bangalore
AWS Training Institutes in Bangalore
Cloud Computing courses in Bangalore
I recently came across your article and have been reading along. I want to express my admiration of your writing skill and ability to make readers read from the beginning to the end.
ReplyDeleteAWS Training in Pune
Thank you for introducing like this tool. keep it update.
ReplyDeleteAWS Training
AWS Course